Posted in : Machine Learning
Machine Learning - Introduction
Machine learning is the study and construction of algorithms that are able to learn from example data or past experience.
Well-posed learning problem
If the learning problem is well posed then:
a computer program is said to learn from experience E with respect to a class of tasks T and performance measure P if its performance at tasks T, as measured by P, improves with experience E.
Example of learning problems
Programming with data
We are searching for an adaptive, robust and fault tolerant system. In order to obtain this we need to go through some automated learning mechanism because rule-based implementations are:
- difficult to program
- brittle, because it miss many edge-cases
- difficult to maintain
- often doesn’t work well (e.g. OCR)
Problem prototypes
Supervised Learning
Using a supervised learning mechanism we can infer a function from labeled training data:
The training data consist of training examples. Each training example is a pair consisting of an input vector and a desired output value.
Examples of supervised learning algorithms:
- Binary classification. Given find in .
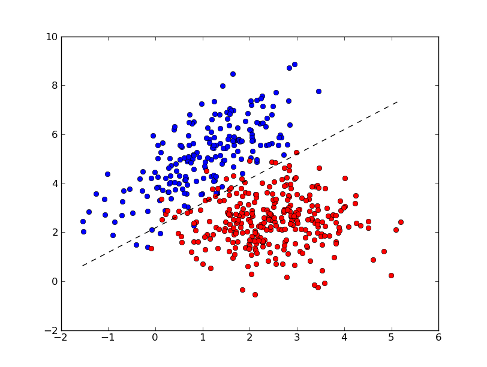
- Multiclass classification. Given find in .

- Regression. Given find in (or ).

In order to measure how well a function fits the training data, we can define a loss function .
Unsupervised Learning
The unsupervised learning algorithms try to find hidden structures in unlabeled data. Since the training example are unlabeled, there is no loss function that we can specify to evaluate a potential solution.
Examples of unsupervised learning algorithms:
- Clustering. Find a set of prototypes representing the data.
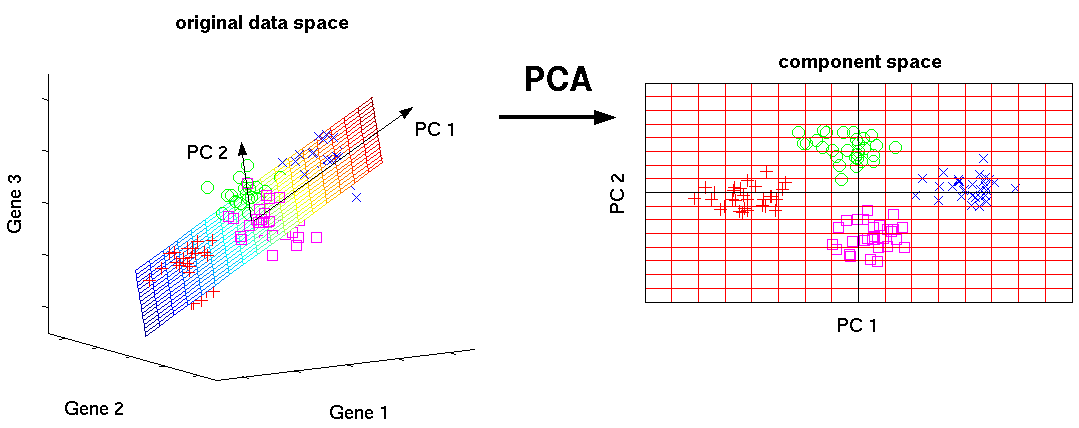
- Principal components. Find a subspace representing the data.
Discriminative Models
The discriminate models are used to express the dependence of an un-observable variable on an observable variable . This is done modelling the conditional probability distribution , which can be used for predicting from .
This approach often offer better convergence and simpler solution to the problem.
Generative Models
The generative model is fully probabilistic, in such that it can be used to generate values of any variable in the model, whereas a discriminative model allows only sampling of the target variables conditional on the observed quantities.
It estimate the joint distribution , from which we can infer by applying the Bayes Rule.
Using this approach we need to observe the data and to estimate the distribution of the data. It is good for missing variables and it’s easy to add prior knowledge about data.